매년 점점 더 많은 자율 주행 차가 도로에서 테스트되고 있습니다. 일부는 이미 특정 지역에 제한된 서비스를 제공하는 반면 다른 일부는 완전히 자율적 일 때 유통됩니다. 이 기사에는 프랑스의 자율 주행 차 테스트 목록이 포함되어 있습니다. 모두 같은 방식으로 설계되지는 않았습니다. 환경을 식별하기 위해 일부는 카메라와 레이더 만 사용하고 다른 일부는 Lidar 센서 (레이저)를 사용합니다. 이 주제에 대해 열정적으로 Udacity의 Self-Driving Car Engineer Nanodegree 프로그램에 등록했으며 처음 두 학기를 마쳤습니다.
인공 지능은 자율 주행 자동차, 특히 환경에 대한 인식의 모든 곳에 있습니다.
카메라로 환경을 인식하는 방법은 무엇입니까?
아래 이미지는 자율 주행 차량의 4 가지 주요 단계를 보여줍니다.

컴퓨터 비전과 센서 퓨전을 Perception이라고합니다. 환경을 이해하는 것입니다.
Computer Vision은 카메라를 사용합니다. 이것은 자동차, 보행자, 도로를 식별 할 수 있습니다 ...
Sensor Fusion은 Radar 및 Lidar와 같은 다른 센서의 데이터를 사용하고 병합하여 카메라에서 얻은 데이터를 보완합니다. 이를 통해 카메라로 식별되는 물체의 위치와 속도를 추정 할 수 있습니다.
현지화는 GPS보다 자동차를 더 정확하게 찾을 수있는 단계입니다.
경로 계획은 자율 주행 차량의 두뇌를 구현합니다. Path Planner는 처음 두 단계의 데이터를 사용하여 A 지점에서 B 지점으로 궤적을 생성하기 위해 차량, 보행자, 주변 물체가 수행 할 작업을 예측합니다.
contrtol 는 마지막 단계입니다. 이 단계는 생성 된 궤도를 기반으로하며 차량을 작동시키기 위해 컨트롤러를 사용합니다.
컴퓨터 시각 인식
Computer Vision은 카메라가 장착 된 컴퓨터가 해당 환경을 이해할 수 있도록하는 분야입니다.
컴퓨터 비전 기술은 보행자 또는 기타 물체를 감지하기 위해 자율 주행 차량에 사용되지만 이미지의 이상을 찾아 암 진단에도 사용할 수 있습니다.
그들은 매우 고전적인 방식으로 선과 색의 감지에서 인공 지능에 이르기까지 갈 수 있습니다.
컴퓨터 비전은 50 년대에 특정 물체의 모양을 기록 할 때 시작되었습니다. 세기 말에 우리는 이미지에서 색상의 진화를 구별 할 수있는 Canny-edge 검출과 같은 기술을 개발하게되었습니다.

2001 년 Viola-Jones 알고리즘은 컴퓨터가 얼굴을 인식하는 능력을 보여줍니다.
다음 몇 년 동안 머신 러닝은 HOG (Histogram of Oriented Gradients) 및 분류기를 광범위하게 사용하여 객체 감지에 널리 사용되었습니다. 목표는 다른 방향 (그라데이션)을 인식하여 객체의 모양을 인식하도록 모델을 훈련시키는 것입니다. 방향 그라디언트의 히스토그램은 각 픽셀의 모양과 방향을 유지합니다. 더 넓은 지역에 걸쳐 평균.

딥 러닝은 강력한 GPU (연속 병렬 작업을 허용하는 그래픽 프로세서 장치)가 도착하고 데이터가 축적되어 성능이 매우 인기를 얻었습니다. GPU 이전에는 머신에서 딥 러닝 알고리즘이 작동하지 않았습니다.
컴퓨터 비전은 세 가지 접근 방식으로 수행 할 수 있습니다.
-인공 지능이 없으면 모양과 색상을 분석하여
-기계 학습에서 기능 학습
-딥 러닝에서 혼자 학습하십시오.
기계 학습
머신 러닝은 컴퓨터 비전에서 모양을 식별하는 방법을 배우기 위해 사용되는 학문입니다.
학습에는 두 가지 유형이 있습니다.
지도 학습을 통해 학습 데이터베이스에서 규칙을 자동으로 만들 수 있습니다.
우리는 구별합니다 :
분류 : 데이터가 한 클래스에 속하는지 다른 클래스에 속하는지 예측합니다. (예 : 개 또는 고양이).
회귀 : 다른 데이터를 기반으로 한 데이터를 예측합니다.
(예 : 크기 또는 우편 번호를 기준으로 한 주택 가격)
비지도 학습은 유사한 데이터가 자동으로 그룹화됨을 의미합니다.
자동차 감지를위한지도 학습 과정에는 4 가지 단계가 있습니다.
첫 번째는 자동차 및 도로 이미지 데이터베이스를 만드는 것입니다. 지도 학습은 어떤 이미지가 자동차에 해당하고 어떤 이미지가 배경을 나타내는지를 나타냅니다. 이것을 라벨링이라고합니다.
2. 어떤 기능이 자동차에 속하는지 확인하기 위해 색상 공간이 다른 이미지를 시도합니다. HOG 기능을 사용하여 양식을 얻습니다.
이미지가 특징 벡터로 변환됩니다.
3. 이들 벡터는 연결되어 트레이닝베이스로서 사용된다. 아래 그래프에서 모양과 색상은 세로 및 가로 축에 표시됩니다.
우리 수업은 블루 포인트 (차)와 오렌지 하나 (비차)입니다. 또한 분류자를 선택해야합니다.
기계 학습 알고리즘은 기능에 따라 두 클래스를 분리하는 선을 그리는 것을 의미합니다. 새로운 점들 (백색 십자선)은 선에 대한 위치에 따라 예측됩니다. 교육 데이터가 많을수록 예측이 더 정확 해집니다.
4. 마지막 단계는 예측입니다. 이미지를 통과하는 알고리즘을 구현하고 훈련에 사용 된 것과 동일한 기능으로 벡터로 변환합니다. 이미지의 각 부분이 분석되어 자동차 주변에 경계 상자를 그리는 분류기로 전달됩니다.
신경망
신경망은 기계 학습 알고리즘을 사용하여 입력 이미지를 가져 와서 차량 수와 위치를 반환합니다. 이 알고리즘은 인공 뉴런을 상호 연결하여 인간 두뇌의 기능을 시뮬레이션합니다.

위의 다이어그램에서 각 원은 퍼셉트론 (Perceptron)이라는 뉴런을 나타냅니다. 왼쪽의 항목은 중앙의 뉴런 층으로 전송됩니다. 뉴런 사이의 각 연결에는 가중치 W (매개 변수에 대한 중요성)가 있습니다. 알고리즘의 목표는 이러한 가중치를 최적화하는 것입니다. 클래스를 예측하기 위해 중앙 레이어의 각 뉴런에서 작업이 수행됩니다. 각 클래스는 출력 뉴런으로 표시됩니다.

각 뉴런에는 기능에 따라 데이터를 분류하는 알고리즘이 있습니다. 많은 양의 데이터로 모델을 훈련 할 때 네트워크는 어떤 가중치가 다른 가중치보다 더 중요한지를 알게됩니다. 목표는 클래스를 완벽하게 분리하는 것입니다.
훈련하기 위해 네트워크는 먼저 가중치를 무작위로 설정하고 포인트가 올바르게 분류되었는지 확인합니다. 포인트의 일부는 아닙니다. 그런 다음 가중치를 한 방향으로 매우 약간 조정하고 함수로 계산 된 오류가 감소하는지 확인합니다. 훈련 데이터를 올바르게 분류하는 라인이 생길 때까지 수백 번 작업을 반복합니다.
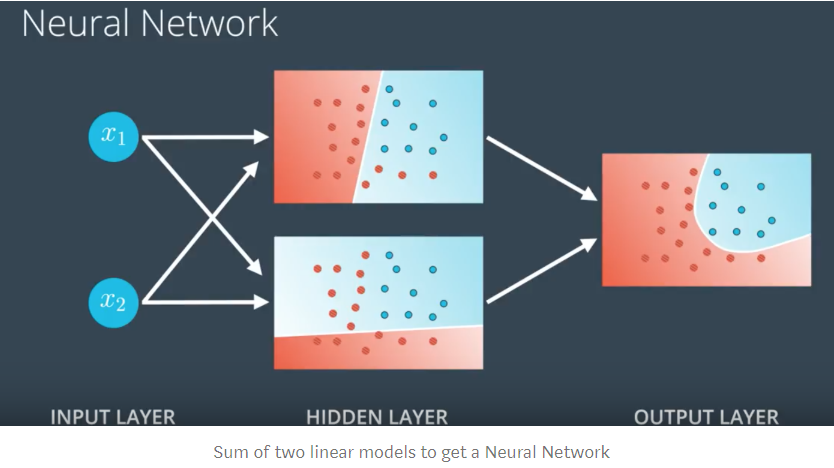
비선형 데이터를 처리하기 위해 신경망은 두 개의 선형 모델의 합을 계산하여 결합합니다. 사용 된 분류 기가 기존 기계 학습 분류기와 다르기 때문에 Gradient Decent 이라는 프로세스를 사용합니다.
신경망이 기존 알고리즘보다 성능이 뛰어나면 특성이나 가중치를 선택하지 않기 때문에 블랙 박스라는 단점이 있습니다. 알고리즘은 데이터와 레이블에 따라 혼자 추측합니다.
딥 러닝이란 무엇입니까?
신경망은 다른 기계 학습 알고리즘보다 성능이 뛰어납니다.
딥 러닝이란 무엇이며 왜 그렇게 인기가 있습니까?

신경망의 다중 계층은 단일 계층보다 더 복잡한 작업에서 더 나은 결과를 제공합니다. 모델이 많을수록 선형성이 떨어지기 때문에 잘못 분류 된 점이 줄어 듭니다.
더 많은 매개 변수와 난이도 데이터 일수록 심층 신경망이 더 유용하고 효과적입니다.
무엇보다도, 다층화의 장점이 있습니다 : 뉴런의 출력 (클래스가 될 가능성)은 다음 뉴런의 입력에 사용됩니다 : 이것을 피드 포워드라고합니다.

DNN (Deep Neural Networks)은 매우 효과적이며 오늘날 음성 지원, 이미지 분석과 같은 대부분의 복잡한 문제에 사용됩니다. 머신 러닝의이 하위 부분은 광범위한 도메인에서 다른 알고리즘보다 성능이 뛰어납니다.
딥 러닝 및 이미지 인식 : CNN
딥 러닝은 많은 머신 러닝 알고리즘보다 성능이 뛰어납니다. 단순한 선형 작업 외에도 이미지 분석과 같은 특정 문제에 적용 할 수 있습니다.
이미지 분석에서 우리는 일반적으로 CNN : Convolutional Neural Networks 또는 ConvNets라는 용어로 딥 러닝에 대해 이야기합니다. CNN은 네트워크에서 가중치를 공유하는 신경망입니다.
이것은 컨볼 루션 (convolution)이라고하는 연산에 의해 처리됩니다. 이러한 작업은 신경망을 통해 이미지의 작은 부분을 전달한 다음 학습하려는 객체의 모양 만 유지하여 전체 이미지를 탐색합니다. 우리는 각 작업에서 객체의 특성을 추출합니다. 그런 다음이 객체의 가중치가 네트워크 전체에서 공유되고 새 이미지마다 최적화됩니다.
여러 이미지에서 반복되는 객체의 형태를 인식하고 이러한 형태로 네트워크를 훈련시킵니다.

CNN은 객체를 인식하기 위해 복잡한 수준에 따라 다른 계층을 학습시킵니다.

이 예에서 첫 번째 레이어는 원과 선과 같은 간단한 모양을 배우고 다음 레이어는 객체가 전체적으로 어떻게 보이는지 알 때까지 약간 더 복잡한 모양을 배우게됩니다. 기능을 수동으로 선택하는 기계 학습과 달리 CNN은 여기서 선택할 기능과 유지할 모양 만 학습합니다. 단순한 신경망과 달리 이미지 분석과 같은 복잡한 작업을 처리 할 수 있습니다. 교육은 기계 학습보다 훨씬 길며 최대 며칠이 걸릴 수 있습니다. 반면에 탐지는 매우 빠르고 안정적입니다.
https://towardsdatascience.com/ai-and-the-vehicle-went-autonomous-e176c73239c6
Every year, more and more autonomous cars are being tested on our roads. Some already offer their restricted services to certain areas while others will be in circulation when fully autonomous. This article contains a map listing autonomous vehicle tests in France. Not all are designed the same way. To identify its environment, some use only a camera and radars while others also use Lidar sensors (laser). Passionate about the subject, I enrolled in the Self-Driving Car Engineer Nanodegree program by Udacity, and I completed the first two terms.
Artificial intelligence is everywhere in self-driving cars, and especially in the perception of the environment.
How to perceive an environment with a camera?
The image below shows four main steps in the operation of an autonomous vehicle.
- Computer Vision and Sensor Fusion are called Perception. It’s about understanding the environment.
Computer Vision uses a camera. This allows to identify cars, pedestrians, roads, …
Sensor Fusion uses and merges data from other sensors such as a Radar and a Lidar to complement those obtained by the camera. This makes it possible to estimate the positions and speeds of the objects identified by the camera. - Localization is the step that can locate a car more precisely than a GPS would.
- Path Planning implements the brain of an autonomous vehicle. A Path Planner uses the data from the first two steps to predict what vehicles, pedestrians, objects around them will do to generate trajectories from point A to point B.
- Control is the final step. This step is based on the created trajectory and uses controllers to actuate the vehicle.
Computer Vision
Computer Vision is a discipline that allows a computer equipped with a camera to understand its environment.
Computer vision techniques are used in autonomous vehicles to detect pedestrians or other objects, but can also be used to diagnose cancers by looking for abnormalities in images.
'자율주행 관련 번역 방' 카테고리의 다른 글
| Transform Configuration (0) | 2020.02.25 |
|---|---|
| map odometry (0) | 2020.02.24 |
| 칼만 필터 [일부 번역] (0) | 2020.02.09 |
| 오토파일럿 홈페이지 [번역] (0) | 2020.02.07 |
| 모빌아이 차량 충돌방지와 인공지능[번역] (0) | 2020.01.27 |


