[대략 번역 요약 글] autonomous machine 를위한 NVIDIA AGX 시스템의 구성원 인 Jetson AGX Xavier는 첨단 AI 및 컴퓨터 비전을 엣지에 배치하는 데 이상적이며 워크 스테이션 수준의 성능을 갖춘 현장에서 로봇 플랫폼을 가능하게 합니다.
(다 읽어보면 결론은 어차피 임베디드로서는 최고 성능 GPU 장치라는..
그러게요.. 진심 조금만 더 가벼우면 좋겠어요..ㅜㅜ)
(2020년 1월 추가 덧글)
왠만하면 시작할때 다음과 같이 fan 을 켜고 사용하는게 좋겠어요..
sudo sh -c 'echo 255 > /sys/devices/pwm-fan/target_pwm'
여기에는 고급 수준의 실시간 인식 및 추론이 필요한 패키지 배송 및 산업 검사가 포함됩니다. Jetson AGX Xavier의 고성능은 로봇 공학 및 엣지 컴퓨팅을 위해 특별히 설계된 세계 최초의 컴퓨터로서 차세대 로봇에 중요한 시각 측정법, 센서 융합, 현지화 및 매핑, 장애물 감지 및 경로 계획 알고리즘을 처리 할 수 있습니다.

Jetson AGX Xavier는 최고 32 개의 TeraOPS (TOPS) 피크 컴퓨팅 및 컴팩트한 100x87mm form-factor 에서750Gbps의 고속 I/O로 GPU 워크스테이션 급 성능을 제공합니다.
사용자는 애플리케이션에 필요한대로 10W, 15W 및 30W에서 작동 모드를 구성 할 수 있습니다.

이를 통해 개발자는 로봇 공학, 지능형 비디오 분석, 의료 기기, 임베디드 IoT edge device 등과 같은 응용 프로그램에 가속화 된 AI를 배포 할 수 있습니다.
이전의 Jetson TX1 및 TX2와 마찬가지로 Jetson AGX Xavier는 System-on-Module (SoM) paradigm 을 사용합니다. 모든 프로세싱은 컴퓨팅 모듈에 내장되어 있으며 고속 I/O는 고밀도 보드-보드 커넥터를 통해 제공되는 breakout carrier 나 enclosure에 있습니다. 이러한 방식으로 모듈의 기능을 캡슐화하면 개발자가 Jetson Xavier를 자신의 디자인에 쉽게 통합 할 수 있습니다.
Table 1: Jetson AGX Xavier System-on-Module features and capabilities
| NVIDIA Jetson AGX Xavier Module | |
| CPU | 8-core NVIDIA Carmel 64-bit ARMv8.2 @ 2265MHz |
| GPU | 512-core NVIDIA Volta @ 1377MHz with 64 TensorCores |
| DL | Dual NVIDIA Deep Learning Accelerators (DLAs) |
| Memory | 16GB 256-bit LPDDR4x @ 2133MHz | 137GB/s |
| Storage | 32GB eMMC 5.1 |
| Vision | (2x) 7-way VLIW Vision Accelerator |
| Encoder* | (4x) 4Kp60 | (8x) 4Kp30 | (16x) 1080p60 | (32x) 1080p30 Maximum throughput up to (2x) 1000MP/s – H.265 Main |
| Decoder* | (2x) 8Kp30 | (6x) 4Kp60 | (12x) 4Kp30 | (26x) 1080p60 | (52x) 1080p30 Maximum throughput up to (2x) 1500MP/s – H.265 Main |
| Camera† | (16x) MIPI CSI-2 lanes, (8x) SLVS-EC lanes; up to 6 active sensor streams and 36 virtual channels |
| Display | (3x) eDP 1.4 / DP 1.2 / HDMI 2.0 @ 4Kp60 |
| Ethernet | 10/100/1000 BASE-T Ethernet + MAC + RGMII interface |
| USB | (3x) USB 3.1 + (4x) USB 2.0 |
| PCIe†† | (5x) PCIe Gen 4 controllers | 1×8, 1×4, 1×2, 2×1 |
| CAN | Dual CAN bus controller |
| Misc I/Os | UART, SPI, I2C, I2S, GPIOs |
| Socket | 699-pin board-to-board connector, 100x87mm with 16mm Z-height |
| Thermals‡ | -25°C to 80°C |
| Power | 10W / 15W / 30W profiles, 9.0V-20VDC input |
| *Maximum number of concurrent streams up to the aggregate throughput. Supported video codecs: H.265, H.264, VP9 Please refer to the Jetson AGX Xavier Module Data Sheet §1.6.1 and §1.6.2 for specific codec and profile specifications. †MIPI CSI-2, up to 40 Gbps in D-PHY V1.2 or 109 Gbps in CPHY v1.1 SLVS-EC, up to 18.4 Gbps ††(3x) Root Port + Endpoint controllers and (2x) Root Port controllers ‡Operating temperature range, Thermal Transfer Plate (TTP) max junction temperature. |
|
Jetson AGX Xavier에는 750Gbps 이상의 고속 I/O가 포함되어있어 스트리밍 센서 및 고속 주변 장치에 큰 대역폭을 제공합니다. PCIe Gen 4를 지원하는 최초의 임베디드 장치 중 하나이며 5 개의 PCIe Gen 4 컨트롤러에 16 개의 레인을 제공합니다. 16 개의 MIPI CSI-2 레인은 4 개의 4 레인 카메라, 6 개의 2 레인 카메라, 6 개의 1 레인 카메라 또는 최대 6 개의 카메라 조합에 연결될 수 있으며 36 개의 가상 채널을 통해 더 많은 카메라를 동시에 연결할 수 있습니다.

볼타 Volta GPU
아래 그림에 나와있는 Jetson AGX Xavier 통합 Volta GPU는 최대 클럭 주파수가 1.37GHz 인 최대 11 개의 TFLOPS FP16 또는 22 TOPS INT8 컴퓨팅을 위해 512 개의 CUDA 코어와 64 개의 텐서 코어를 제공합니다. sm_72의 계산 기능으로 CUDA 10을 지원합니다. GPU에는 64 개의 CUDA 코어와 8 개의 텐서 코어 (볼타 SM 당)를 갖춘 8 개의 볼타 스트리밍 멀티 프로세서 (SM)가 포함되어 있습니다. 각 Volta SM에는 이전 세대보다 8 배 큰 128KB L1 캐시가 포함되어 있습니다. SM은 512KB L2 캐시를 공유하며 이전 세대보다 4 배 빠른 액세스를 제공합니다.

각 SM은 CUDA 코어 및 텐서 코어와 함께 자체 L0 명령어 캐시, 워프 스케줄러, 디스패치 유닛 및 레지스터 파일을 포함하는 SMP (스트리밍 멀티 프로세서 파티션)라고하는 4 개의 개별 처리 블록으로 구성됩니다. Pascal보다 SM 당 2 배의 SMP 수를 가진 Volta SM은 동시성이 향상되었으며 더 많은 스레드, 워프 및 스레드 블록을 지원합니다.
Tensor Cores
NVIDIA Tensor Cores는 CUDA 코어와 함께 동시에 실행되는 프로그래밍 가능한 fused matrix-multiply-and-accumulate units 입니다. Tensor Core 는 dense linear algebra 계산, 신호 처리 및 딥러닝 추론을 가속화하기 위해 새로운 부동 소수점 HMMA (Half-Precision Matrix Multiply and Accumulate) 및 IMMA (Integer Matrix Multiply and Accumulate) 명령을 구현합니다.
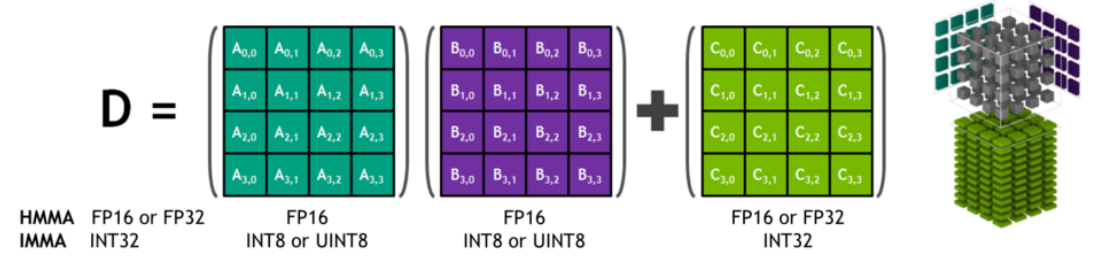
딥 러닝 가속기
Jetson AGX Xavier에는 fixed-function CNN (Convolutional Neural Networks)의 추론을 오프로드하는 두 개의 NVIDIA DLA (Deep Learning Accelerator) 엔진이 아래 그림에 나와 있습니다. 이 엔진은 에너지 효율성을 향상시키고 보다 복잡한 네트워크 및 동적 작업을 실행합니다. 각 DLA는 0.5-1.5W의 전력 소비로 최대 5 개의 TOPS INT8 또는 2.5 TFLOPS FP16 성능을 제공합니다. DLA는 convolution, deconvolution, activation functions, min/max/mean pooling, local response normalization, 그리고 fully-connected layers과 같은 CNN 계층 가속화를 지원합니다.

딥 러닝 추론 벤치 마크
Jetson AGX Xavier의 GPU 및 DLA 엔진에서 TensorRT 5.0과 함께 JetPack 4.1.1 Developer Preview 릴리스를 사용하여 ResNet, GoogleNet 및 VGG 등에 대해 벤치 마크를 실행했습니다. GPU와 두 개의 DLA는 각각 동일한 구성으로 INT8 및 FP16 정밀도로 동일한 네트워크 아키텍처를 동시에 실행했으며 각 구성에 대한 총 성능이 보고되었습니다. GPU와 DLA는 실제 사용 사례에서 서로 다른 네트워크 또는 네트워크 모델을 동시에 실행하여 병렬 또는 처리 파이프 라인에서 서로 고유 한 기능을 제공 할 수 있습니다. TensorRT에서 INT8과 전체 FP32 정밀도를 사용하면 정확도 손실이 1 % 이하입니다.
먼저 의미 분할에 사용되는 2048 × 1024 해상도의 풀 HD 모델 인 ResNet-18 FCN (Fully Convolutional Network)의 결과를 살펴 보겠습니다. 세그먼트 화는 자유 공간 감지 및 점유 매핑과 같은 작업에 대한 픽셀 별 분류를 제공하며 인식, 경로 계획 및 탐색을 위해 자율 머신에서 계산 된 딥 러닝 워크로드를 나타냅니다. 그림 6은 Jetson AGX Xavier와 Jetson TX2에서 ResNet-18 FCN 실행의 측정 처리량을 보여줍니다.

너무 길어서 정리하다가 숨이 넘어가네요.
cameal 이랑 video 가속기만 남았는데 너무 힘들어서 나머지는 다음에 ㅠㅠ..
원문 : https://devblogs.nvidia.com/nvidia-jetson-agx-xavier-32-teraops-ai-robotics/
'Nvidia Jetson' 카테고리의 다른 글
| Nvidia Jetson CAN 통신 (6) | 2020.01.01 |
|---|---|
| Nvida Jetson 에서 SSD inference 속도 (1) | 2019.11.06 |
| Jetson TX2에서 pca9685 로 서보 모터 놀이하기 (1) | 2019.09.30 |
| Jetson 에서 터틀이 가상 SLAM/Navi 놀이. (0) | 2019.09.22 |



